PipelineJobs¶
Essential details of a computation workflow are represented in a Pipeline comprised of static software components and parameterizations. The invocation of a pipeline, complete with linkages to experimental metadata, inputs, and run-time parameterization is represented in a PipelineJob.
Creation, management, and metadata resolution of Pipelines and PipelineJobs
is implemented in the python-datacatalog library (this codebase) which is
operated by interlinked Abaco Reactors collectively known as the PipelineJobs
System. These Reactors write and mantain records and linkages in the MongoDB
databases that form the Data Catalog. They are documented in
Manager Reactors.
Overview¶
Each PipelineJob is an entry in the Data Catalog jobs collection representing one and only one combination of:
- Specific pipeline
- Linkage to specific measurements
- Run-time parameterizations
This design ensures that any given combination of these values will always be associated with a distinct set of output files (i.e. sequence alignments, CSVs, data frames, PDF reports, etc.). This design permits a strong guarantee that those results can always be specifically accessed and referred to in the future, whether by human-led or automated processes.
Job Lifecycle¶
A PipelineJob has a defined set of states transitions between during key stages of the analytics lifecycle. Such transitions occur when by way of events, as illustrated here:
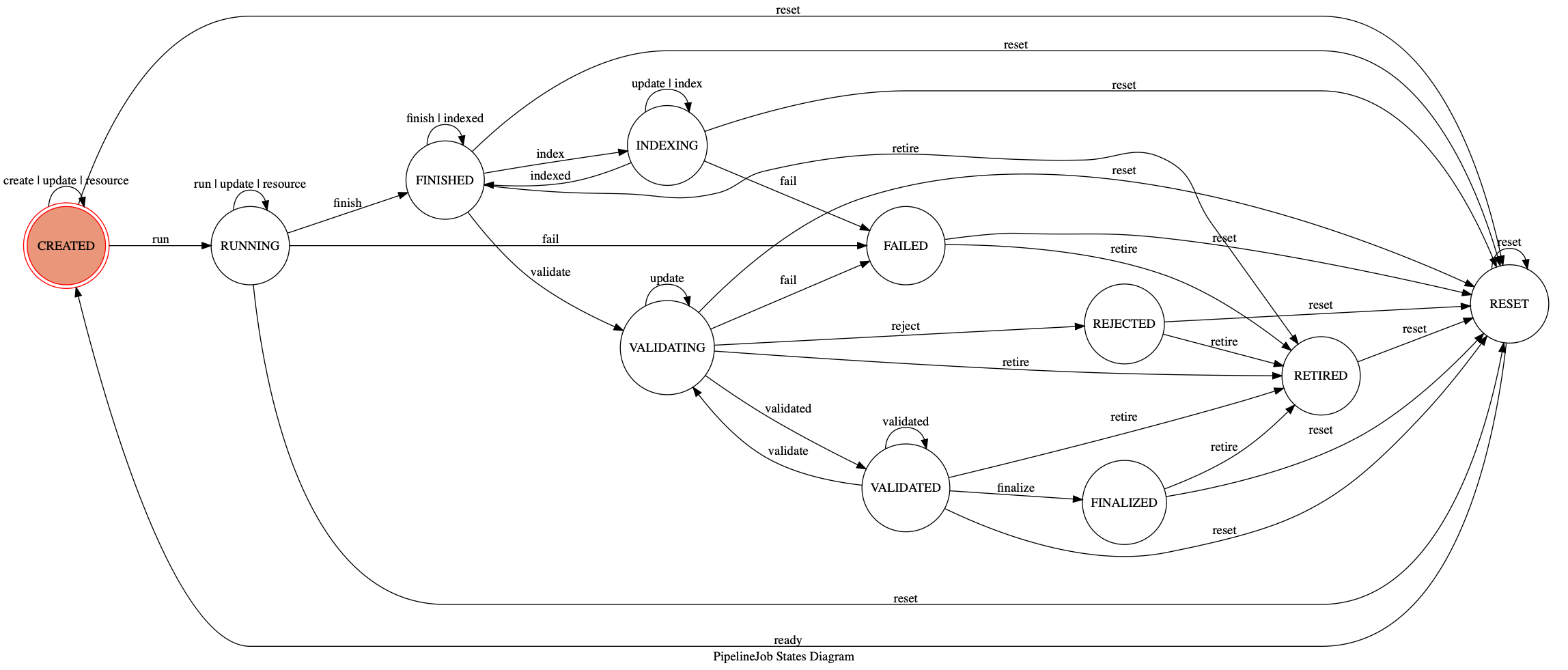
These states and events are described in detail in the tables below (in approximately chronological order).
States¶
| State | Description |
|---|---|
| CREATED | Job inputs and configuration has been defined |
| RUNNING | Job is actively processing data |
| FAILED | Job did not complete successfully |
| FINISHED | Job has completed processing and outputs are archived |
| INDEXING | Job outputs are being associated with project metadata |
| VALIDATING | Job outputs are being assessed for correctness |
| VALIDATED | Job outputs were determined to be correct |
| REJECTED | Job outputs are invalid and should not be used |
| FINALIZED | Job outputs are validated and ready for general use |
| RETIRED | Job and outputs should no longer be used |
| RESET | Job and outputs are being reset for another run |
Events¶
| Event | Description |
|---|---|
| create | Create a new job |
| run | Mark the job as “running” |
| update | Append an information item to the job history |
| resource | Note resource marshalling activity in the job history |
| fail | Permanently mark the job as failed |
| finish | Mark the job as complete |
| index | Index the job outputs |
| indexed | Mark that the indexing task is complete |
| validate | Mark the job as under validation |
| validated | Mark that validation has completed |
| finalize | Mark the job and its outputs as suitable for use |
| reject | Mark the job and its outputs as unsuitable for use |
| retire | Mark job and its outputs as retired/deprecated |
| reset | Begin to reset the job, erasing archive_path contents |
| ready | Complete the reset process, allowing job to be re-run |
Job Schema¶
A PipelineJob has four _core_ properties:
dataThe run-time parameterization of the pipelinehistoryChronological history of state-change eventstateCurrent state of the jobuuidUUID5 hashed from thepipeline_uuidand jobdata
It also has four relationship linkages to other assets in the Data Catalog. These are actively maintained and curated by the PipelineJobs System.
generated_byThe UUID of a Pipeline that performed the workchild_ofUUID(s) of measurements analysed by the job.acted_onMembers of the file collection processed by the jobacted_usingMembers of the references collection used by the job